

While XGBoost and LightGBM reigned the ensembles in Kaggle competitions, another contender took its birth in Yandex, the Google from Russia. It decided to take the path less tread, and took a different approach to Gradient Boosting. They sought to fix a key problem, as they see it, in all the other GBMs in the world.
Let’s take a look at what made it different:
Categorical Encoding
Let’s take a look at the innovation which gave the algorithm it’s name – CatBoost. Unlike XGBoost, CatBoost deals with Categorical variables in a native way. Many studies have shown that One-Hot encoding high cardinality categorical features is not the best way to go, especially in tree based algorithms. And other popular alternatives all come under the umbrella of Target Statistics – Target Mean Encoding, Leave-One-Out Encoding, etc.
The basic idea of Target Statistics is simple. We replace a categorical value by the mean of all the targets for the training samples with the same categorical value. For example, we have a Categorical value called weather, which has four values – sunny, rainy, cloudy, and snow. The most naive method is something called Greedy Target Statistics, where we replace “sunny” with the average of the target value for all the training samples where weather was “sunny”.
If M is the categorical feature we are encoding and 


But this is unstable when the number of samples with
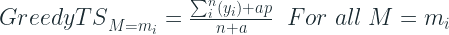
where a > 0 is a parameter. A common setting for p (prior) is the average target value in the dataset.
But these methods usually suffer from something called Target Leakage because we are using our targets to calculate a representation for the categorical variables and then using those features to predict the target. Leave-One-Out Encoding tries to reduce this by excluding the sample for which it is calculating the representation, but is not fool proof.
CatBoost authors propose another idea here, which they call Ordered Target Statistics. This is inspired from Online Learning algorithms which get the training examples sequentially in time. And in such cases, the Target Statistics will only rely on the training examples in the past. To adapt this idea to a standard offline training paradigm, they imagine a concept of artificial time, but randomly permuting the dataset and considering them sequential in nature.
Then they calculate the target statistics using only the samples which occured before that particular sample in the artificial time. It is important to note that if we use just one permutation as the artificial time, it would not be very stable and to this end they do this encoding with multiple permutations.
Ordered Boosting
The main motivation for the CatBoost algorithm is, as argued by the authors of the paper, the target leakage, which they call Prediction Shift, inherent in the traditional Gradient Boosting models. The high-level idea is quite simple. As we know, any Gradient Boosting model works iteratively by building base learners over base learners in an additive fashion. But since each base learner is build based on the same dataset, the authors argue that there is a bit of target leakage which affects the generalization capabilities of the model. Empirically, we know that Gradient Boosted Trees has an overwhelming tendency to overfit the data. The only countermeasures against this leakage are features like subsampling, which they argue is a heuristic way of handling the problem and only alleviates it and not completely removes it.
The authors formalize the proposed target leakage and mathematically show us that it is present. Another interesting observation that they had is that the target shift or the bias is inversely proportional to the size of the dataset, i.e. if the dataset is small, the target leak is much more pronounced. This observation also agrees with our empirical observation that Gradient Boosted Trees tend to overfit to a small dataset.
To combat this issue, they propose a new variant of Gradient Boosting, called Ordered Boosting. The idea, at it’s heart, is quite intuitive. The main problem with previous Gradient Boosting was the reuse of the same dataset for each iteration. So, if we have a different dataset for each of the iteration, we would be solving the problem of leakage. But since none of the datasets are infinite, this idea, purely applied, will not be feasible. So, the authors have proposed a practical implementation of the above concept.
It starts out with creating s+1 permutations of the dataset. This permutation is the artificial time that the algorithm takes into account. Let’s call it 

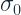
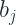
We saw the way CatBoost deals with Categorical variables earlier and we mentioned that there we use multiple permutations to calculate the target statistics. This is implemented as part of the boosting algorithm which uses a particular permutation from
And once all the trees are built, the leaf values of the final model F are calculated by the standard gradient boosting procedure(that we saw in the previous articles) using permutation
One important thing to note it that CatBoost supports the traditional Gradient Boosting also, apart from the Ordered Boosting (boosting_type = ‘Plain’ or ‘Ordered’). If it is ‘Plain’, and there are categorical features, the permutations are still created for the target statistic, but the tree building and boosting is done without the permutations.
Oblivious Trees
CatBoost also differs from the rest of the flock in another key aspect – the kind of trees that is built in its ensemble. CatBoost, by default, builds Symmetric Trees or Oblivious Trees. These are trees the same features are responsible in splitting learning instances into the left and the right partitions for each level of the tree.
This has a two-fold effect in the algorithm –
- Regularization: Since we are restricting the tree building process to have only one feature split per level, we are essentially reducing the complexity of the algorithm and thereby regularization.
- Computational Performance: One of the most time consuming part of any tree-based algorithm is the search for the optimal split at each nodes. But because we are restricting the features split per level to one, we only have to search for a single feature split instead of k splits, where k is the number of nodes in the level. Even during inference these trees make it lightning fast. It was shown to be 8X faster than XGBoost in inference.
Although the default option is “SymmetricTree“, there is also the option to switch to “Depthwise“(XGBoost) or “Lossguide“(LightGBM) using the parameter “grow_policy“,
Categorical Feature Combinations
Another important detail of CatBoost is that it considers combinations of categorical variables implicitly in the tree building process. This helps it consider joint information of multiple categorical features. But since the total number of combinations possible can explode quickly, a greedy approach is undertaken in the tree building process. For each split in the current tree, CatBoost concatenates all previously used Categorical Features in the leaf with all the rest of the categorical features as combinations and target statistics are calculated on the fly.
Overfitting Detector
Another interesting feature in CatBoost is the inbuilt Overfitting Detector. CatBoost can stop training earlier than the number of iterations we set, if it detects overfitting. there are two overfitting detectors implemented in CatBoost –
- IncToDec
- Iter
Iter is the equivalent of early stopping where the algorithm waits for n iterations since an improvement in validation loss value before stopping the iterations
IncToDec is more slightly involved. It takes a slightly complicated route by keeping track of the improvement of the metric iteration after iteration and also smooths the progression using an approach similar to exponential smoothing and sets a threshold to stop training whenever that smoothed value falls below it.
Missing Values
Following XGBoost’s footsteps, CatBoost also deals with missing values separately. There are two ways of handling missing values in CatBoost – Min and Max.
If you select “Min”, the missing values are processed as the minimum value for the feature. And if you select “Max”, the missing values are processed as the maximum value for the feature. In both cases, it is guaranteed that the split between missing values and others are considered in every tree split.
HyperParameters
If LightGBM had a lot of hyperparameters, CatBoost has even more. With so many hyperparameters to tune, GridSearch stops being feasible. It becomes more of an art to get the right combination of parameters for any given problem. But still I’ll try to summarize a few key parameters which you have to keep in mind.
- one_hot_max_size : This sets the maximum number of unique values in a categorical feature below which it will be one-hot encoded and not using Target statistics. It is recommended that you do not do your one-hot encoding before you feed in the feature set, because it will hurt both accuracy and performance of the algorithm.
- iterations – The number of trees to be built in the ensemble. This has to be tuned with a cv or one of the overfitting detection methods should be employed to make the iteration stop at the ideal iteration.
- od_type, od_pval, od_wait – These three parameters configure the overfitting detector.
- od_type is the type of overfitting detector.
- od_pval is the threshold for IncToDec(Recommended Range: [10e-10, 10e-2]). Larger the value, earlier Overfitting is detected.
- od_wait has different meaning depending on the od_type. If it is IncToDec, the od_wait is the number of iterations it has to run before the overfitting detector kicks in. If it is Iter, the od_wait is the number of iterations it will wait without an improvement of the metric before it stops training.
- learning_rate – The usual meaning. But CatBoost automatically set the learning rate based on the dataset properties and the number of iterations set.
- depth – This is the depth of the tree.Optimal values range from 4 to 10. Default Value: 6 and 16 if growing_policy is Lossguide
- l2_leaf_reg – This is the regularization along the leaves. Any positive value is allowed as the value. Increase this value to increase the regularization effect.
- has_time – We have already seen that there is an artificial time which is taken to accomplish ordered boosting. But what if your data actually have a temporal order? In such cases set has_time = True to avoid using permutations in ordered boosting, but instead use the order in which the data was provided as the one and only permutation.
- grow_policy – As discussed earlier, CatBoost builds “SymmetricTree” by default. But sometimes “Depthwise” and “Lossguide” might give better results.
- min_data_in_leaf is the usual parameter to control the minimum number of training samples in each leaf. This can only be used in Lossguide and Depthwise.
- max_leaves is the maximum number of leaves in any given tree. This can only be used in Lossguide. It is not recommended to have values greater than 64 here as it significantly slow down the training process.
- rsm or colsample_bylevel – The percentage of features to be used in each split selection. This helps us control overfitting and the values range from (0,1].
- nan_mode – Can take values “Forbidden”, “Min”, “Max” as the three options. “Forbidden” does not allow missing values and will throw an error. Min and Max we have discussed earlier.
In the next part of our series, let’s look at the new kid on the block – NgBoost
- Part I – Gradient boosting Algorithm
- Part II – Regularized Greedy Forest
- Part III – XGBoost
- Part IV – LightGBM
- Part V – CatBoost
- Part VI(A) – Natural Gradient
- Part VI(B) – NGBoost
- Part VII – The Battle of the Boosters
References
- Friedman, Jerome H. Greedy function approximation: A gradient boosting machine. Ann. Statist. 29 (2001), no. 5, 1189–1232.
- Prokhorenkova, Liudmila, Gusev, Gleb et.al. (2018). CatBoost: unbiased boosting with categorical features. In Advances in Neural Information Processing Systems
- CatBoost Parameters. https://catboost.ai/docs/concepts/python-reference_parameters-list.html

9 thoughts on “The Gradient Boosters V: CatBoost”