

Unlike my regular blog posts, this one is going to be a very short one – crisp and to the point. Deep Learning has been touted as the next big thing in data analytics and things have gotten so hyped that a lot of people (even practitioners) have started to consider it as magic. I’m just trying ground these expectations and breakdown what deep learning really is.
This is for an audience who already have some idea about machine learning, deep learning, and basic linear algebra. So, consider yourself warned.
Linear Algebra – A Preface
We have all learnt Linear Algebra in school. Vectors, Matrices, Matrix Multiplication, Dot Products, are all terms we have heard and learnt how to do these calculations by hand. But how many of us really get Linear Algebra, intuitively. Apart from strange ways to write numbers in a square form and perform opaque and weird multiplication and addition, what do we know about Linear Algebra. This is where a lot of us, including me, lacked. But now, with information at the tip of my fingers, what’s stopping us from learning it the right way?
Grant Sanderson, through his famous youtube channel 3blue1brown, also has a playlist where he goes over similar ideas and makes the intuition of Linear Algebra clear, visually. I highly recommend checking out the playlist to have a solid geometrical interpretation of Linear Algebra. For a more formal treatment, you can take Gilber Strang’s help. Gilbert Strang, a renowned mathematician and educator, has a beautiful and short course on Linear Algebra.
The key point here is the geometric intuition of linear algebra and this is priceless when understanding machine learning and in particular deep learning. Just summarizing a few points here as a refresher:
- A Vector is a point in space.
- When you multiply a vector with a matrix, we are doing a linear transformation and the contents of the matrix defines what transformation we are doing.
- Depending on the contents of matrices, Matrix multiplication does rotation, reflection, scaling, shearing, etc. to the Vector.
The Experiment
Now let’s take a simple classification problem, something which is not linearly separable. We can synthetically generate a spiral dataset as shown below with 2 classes and a 1000 points.
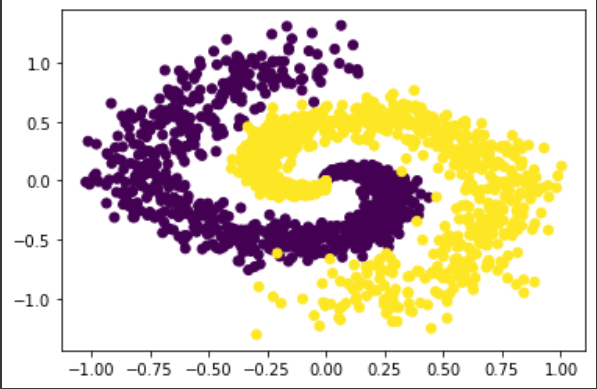
There is no way a linear line is going to separate these classes, right? It’s pretty straightforward to train a Neural Network on this data to classify them with a pretty high accuracy. We are just going to use a two hidden layers with 128 and 2 units, respectively, to do the task, and we get an accuracy of 95%.
Now, the fun starts. Let’s pop the hood and check out what happened.
Decision Boundaries
One of the most popular way of looking at any machine learning model output (especially classification) is by looking at decision boundaries. Linear models will have a straight line as a decision boundary and non-linear models will have curved ones. Let’s see what the decision boundary our neural network learnt.
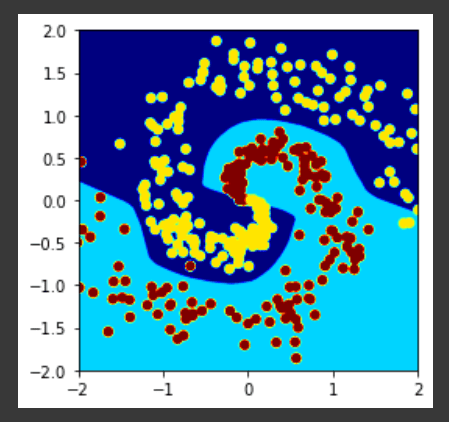
Looks like our network have drawn a non-linear decision boundary as expected.
But there is another way we can look at what happened and that involves the geometric intuition of linear algebra.
Warping of Vector Space
Like we discussed earlier, Neural Networks are a bunch of linear transformations with non-linearities sprinkled in between. And we know that the last layer of a neural network is just a linear layer, right? So, if we consider all the layers before the last layer, all they are doing is apply matrix multiplication and activation functions so that the data becomes linearly separable for the final layer. From the geometric interpretation of linear algebra, we know that a matrix multiplication is just a linear transformation of the vector space.
Let’s now visualize this in the classification problem that we were working on. Below we have visualized the points in original space and then visualized the penultimate layer output of the network.
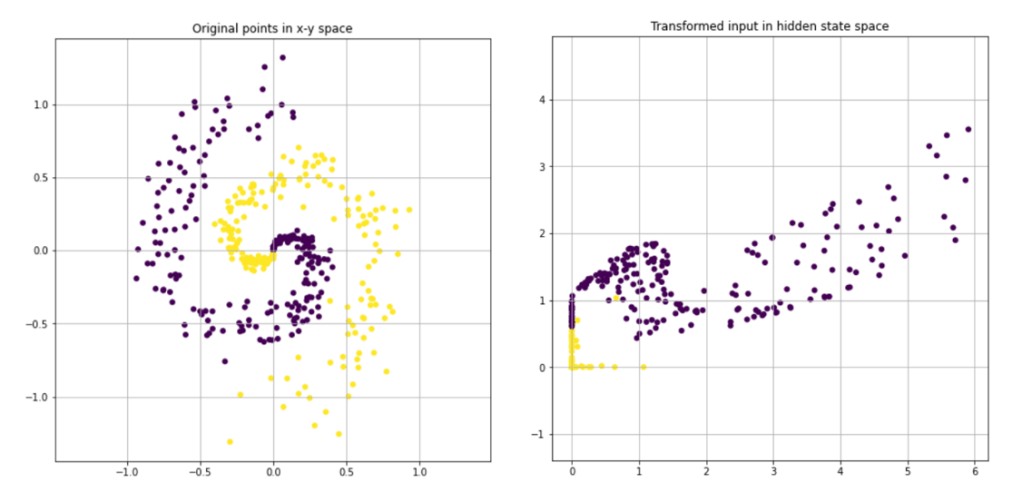
We can see that the points are not linearly separable and the last layer, which is nothing but a linear classifier, can separate these points. Therefore, what the hidden layers have learnt is a transformation from original input space to another space in which the points are linearly separable.
Let’s also see an animation of this process (3blue1brown style), because nothing concretely establishes intuition as a video.
We can see how the neural network warps and folds the space so that the input points become linearly separable.
And this is made possible by the activation function(which in this case is a RELU) which makes this non-linear transformation possible. If there was no activation function, the total transformation would still be linear and would not be able to resolve the non-linearly distributed points to linearly separable ones. Let’s see if the same transformation without activation functions.
Next time an interviewer asks you why we need an activation function, blow his mind by explaining what you mean when you say “activation functions introduce non-linearity”.

Great article. Small correction: We can see that the points are NOW linearly separable and the last layer, which is nothing but a linear classifier, can separate these points.
LikeLike
Great intuition
LikeLike