
If you have tried to understand the maths behind machine learning, including deep learning, you would have come across topics from Information Theory – Entropy, Cross Entropy, KL Divergence, etc. The concepts from information theory is ever prevalent in the realm of machine learning, right from the splitting criteria of a Decision Tree to loss functions in Generative Adversarial Networks.
If you are a beginner in Machine Learning, you might not have made an effort to go deep and understand the mathematics behind the “.fit()“, but as you mature and stumble across more and more complex problems, it becomes essential to understand the math or at least the intuition behind the maths to effectively apply the right technique at the right place.
When I was starting out, I was also guilty of the same. I’ll see “Cross Categorical Entropy” as a loss function in a Neural Network and I take it for granted – that it is some magical loss function that works with multi-class labels. I’ll see “entropy” as one of the splitting criterion in Decision Trees and I just experiment with it without understanding what it is. But as I matured, I decided to spend more time in understanding the basics and it helped me immensely in getting my intuitions right. This also helped in understanding the different ways the popular Deep Learning Frameworks, PyTorch and Tensorflow, have implemented the different loss functions and decide when to use what.
This blog is me summarising my understanding of the underlying concepts of Information Theory and how the implementations differ across the different Deep Learning Frameworks. Each of the concepts that I’ve tried to explain starts off with an introduction and a way to reinforce the intuition, and then provide the mathematics associated with it as a bonus. I’ve always found the maths to clear the understanding like nothing else can.
Information Theory
In the early 20th century, computer scientists and mathematicians around the world were faced with a problem. How to quantify information? Let’s consider the two sentences below:
- It is going to rain tomorrow
- It is going to rain heavily tomorrow
We a humans intuitively understand the both sentences transmit different amounts of information. The second one is much more informative than the first. But, how do you quantify it? How do you express that in the language of mathematics?
Enter Claude E. Shannon with his seminal paper “A Mathematical Theory of Communication”[1]. Shannon introduced the qualitative and quantitative model of communication as a statistical process. Among many other ideas and concepts, he introduced Information Entropy, and the concept of ‘bit’-the fundamental unit of measurement of Information.
Information Theory is quite vast, but I’ll try to summarise key bits of information(pun not intended) in a short glossary.
- Information is considered to be a sequence of symbols to be transmitted through a medium, called a channel.
- Entropy is the amount of uncertainty in a string of symbols given some knowledge of the distribution of symbols.
- Bit is a unit of information, or a sequence of symbols.
- To transfer 1 bit of information means reducing the uncertainty of the recipient by 2
- For eg. In a coin toss, before we see the coin rest, there are two possible outcomes. Once the coin rests and we find that it is heads, the possible outcome become just 1. So in this situation, the transfer of information by the coin toss is 1 bit.
Entropy
Let’s setup an example which we will use to make the intuition behind Entropy clear. The ubiquitous “balls in a box” example is as good as any.
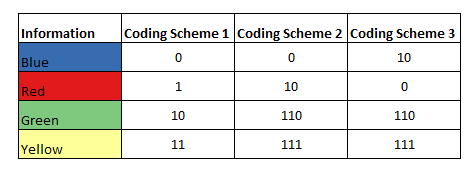
There is a box with 100 balls which have four different colours – Blue, Red, Green and Yellow. Let us assume there are 25 balls of each colour in the box. A transmitter picks up a ball from the container at random and transmits that information to a receiver. For our example, let’s assume that the transmitter is in India and the receiver is in Australia. And let’s also assume that we are in the early 20th century when Telegraphy was one of the primary mode of long distance communication. The thing about telegram messages is that they are charged by the word and so you need to be careful about what you are sending if you are on a budget(this might not seem important right now, but I assure you it will). Adding just one more restriction to the formulation – you cannot send the actual word “blue” through the telegram. You do not have 26 symbols of the English language, but instead just two symbols – 0 and 1.

Now let’s look at how we will be coding the four responses. I’m sure all of you know the binary numerical system. So if we have four outcomes, we can get unique codes using a code length of two. We use that to assign a code for each of our four outcomes. This is fixed length encoding.
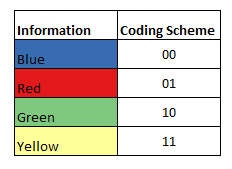
Another way to think about this is in terms of reduction in uncertainty. We know that all the four outcomes are equally likely(each has a probability of 1/4). And when we transmit the information about the colour of the picked ball, we reduce the uncertainty by 4. We know that 1 bit can reduce uncertainty by 2 and to reduce uncertainty by 4 we need two bits.
Mathematically, if we have M symbols in the code we are using, we would need 
What would be the average number of bits we would be using to send the information?

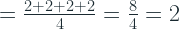
Mean and Expected Values
What is an average? In the world of probability, average or mean is the expected value of a probability distribution.
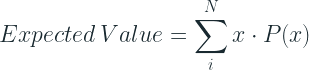
Expected Value can also be thought of this way: If we are to pick a ball at random from the box for 1000 times and record the length of bits that was required to encode that message and take an average of all those 1000 entries, you would get the expected value of the length of bits.
If all outcomes are equally likely, P(x) = 1/N, where N is the number of possible outcomes. And in that case, the expected value becomes a simple mean.


Let’s slightly change the setup of our example. Instead of having equal number of coloured balls, now we have 25 blue balls, 50 red balls, 13 green balls and 12 yellow balls. This example is much better to explain the rest of the concepts and since now you know what an expected value of a probability distribution is, we can follow that convention.
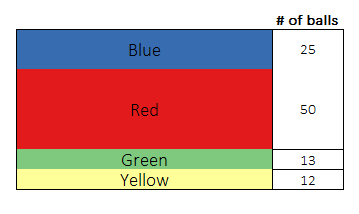

The expected value does not change because no matter which ball you choose, the number of bits you use is still 2.
But, is the current coding scheme the most optimal? This is where Variable Length Coding comes into the picture. Let’s take a look at three different variable coding schemes.
Now that we know how to calculate expected value of the length of bits, let’s calculate it for the three schemes. The one with the lowest length of bits should be the most economical one, right?
Coding Scheme 1:
We are using 1 bit for Blue and Red and 2 bits each for Green and Yellow.
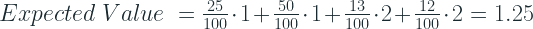
Coding Scheme 2:
We are using 1 bit for Blue, 2 bits for Red and 3 bits each for Green and Yellow.
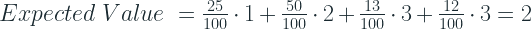
Coding Scheme 3:
We are using 2 bit for Blue, 1 bits for Red and 3 bits each for Green and Yellow.

Coding Scheme 1 is the obvious choice, right? This is where Variable Length Coding gets tricky. If we pick a ball from the box and it was blue. So we send ‘0’ as a message to Australia. And before Australia got a change to read the message, we pick another ball and it was green. So we send ’10’ to Australia. Now when Australia looks at the message queue, they will see ‘010’ there. If it was a fixed length code, we would know that there is a break every n symbols. But in the absence of that, ‘010’ can be interpreted as blue, green or blue, red, blue. That is why a code should be uniquely decodable. A code is said to be uniquely decodable if two distinct strings of symbols never give rise to the same encoded bit string. This results in a scenario where you have to let go of a few codes every extra symbol you add. Chris Olah has a great blog[2] explaining the concept.
That leaves us with Coding Scheme 2 and 3. Both of them are uniquely decodable. The only difference between them is that in Scheme 2 we are using 1 bit for blue and 2 bits for red. Scheme 2 is the reverse. And we know that getting a red ball from the box is much more likely than blue ball. So it makes sense to use the smaller length for the red ball and that is why the expected value of length of bits is lower for Scheme 3 than 2.
Now you would be wondering why we are so concerned about the expected length of bits. This expected length of bits of the best possible coding scheme is what is called the Shannon Entropy or just Entropy. There is just one part of this which is incomplete. How do you calculate the optimum number of bits for a given problem?
The easy answer is the 
And extending it to the whole probability distribution P, we take the expected value:

In our example, it works out to be:

For those who are interested to know how we arrived at the formula, read along.
The Math
While the intuition is useful to get the idea, you can’t really scale it. Every time you get a new problem, you can’t sit down with a paper and pen, figure out the best coding scheme and then calculate the entropy. That’s where the maths comes in.
One of the properties of uniquely decodable codes is something called a prefix property. No codeword should be the prefix of another codeword. This means that every time you choose a code with a shorter length, you are letting go of all the possible codes with that code as the prefix. If we take 01 as a code, we cannot use 011 or 01001, etc. So there is a cost incurred for selecting each code. Quoting from Chris Olah’s blog:
The cost of buying a codeword of length 0 is 1, all possible codewords – if you want to have a codeword of length 0, you can’t have any other codeword. The cost of a codeword of length 1, like “0”, is 1/2 because half of possible codewords start with “0”. The cost of a codeword of length 2, like “01”, is 1/4 because a quarter of all possible codewords start with “01”. In general, the cost of codewords decreases exponentially with the length of the codeword.
Chris Olah’s blog[2]
And that cost can be quantified as

where L is the length of the message. Inverting the equation, we get:
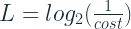
Now what is the cost? Our spends are proportional to how much a particular outcome needs to be encoded. So we spend P(x) for a particular variable x. And therefore the cost = P(x). (For better intuition on this cost read Chris Olah’s Blogpost[2])

Cross Entropy
In our example, now Australia also has a box with the same four coloured balls. But the distribution of the balls are different, as shown below(which is denoted by q)

Now Australia wants to do the same kind of experiments India did and send back the color o the ball they picked. They decided to use the same coding scheme that was set earlier to carry out the communication.
Since the coding scheme is derived from the source distribution, the length of bits for each of the outcome is the same as before. For eg.

But what has changed is the frequency in which the different messages are used. So, now the colour of the ball which Australia draws is going to be Green 50% of the time, and so on. The coding scheme that we have derived for the first use case(India to Australia) is not optimised for the 2nd use case(Australia to India).

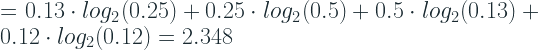
This is the Cross Entropy which can be formally defined as:
where, p(x) is the probability of the distribution which was used to come up with the encoding scheme and q(x) is the probability of the distribution which is using them.
The Cross Entropy is always equal to or greater than the Entropy. In the best case scenario, the source and destination distributions are exactly the same and in that case, the Cross Entropy becomes Entropy because we can substitute q(x) with p(x). In Machine Learning terms, we can say that the predicted distribution is p(x) and the ground truth distribution is q(x). So the more the predicted and true distribution is similar, closer Entropy and Cross Entropy would be.
Kullback-Leibler Divergence
Now that we have understood Entropy and Cross Entropy, we are in a position to understand another concept with a scary name. The name is so scary that even practitioners call it KL Divergence instead of the actual Kullback-Leibler Divergence. This monster from the depths of information theory is a pretty simple and easy concept to understand.
KL Divergence measures how much one distribution diverges from another. In our example, we use the coding scheme we used for communication from India to Australia to do the reverse communication also. In machine learning, this can be though of as trying to approximate a true distribution(p) with a predicted distribution(q). But doing this we are spending more bits than necessary for sending the message. Or, we are having some loss because we are approximating p with q. This loss of information is called KL Divergence.
Two key properties of KL Divergence is worth to note:
- KL Divergence is non-negative. i.e. It is always zero or a positive number.
- KL Divergence is non-symmetric. i.e. KL Divergence from p to q is not equal to KL Divergence of q to p. And because of this, it is not strictly a distance.

KL(P||Q) can be interpreted in the following ways:
- The divergence from Q to P
- The relative entropy of P with respect to Q
- How well Q approximates P
The Math
Let’s take a look at how we arrive at the formula, which will enhance our understanding of KL Divergence.
We know that from our intuition that KL(P||Q) is the information lost when approximating P with Q. What would that be?
Just to recap the analogy of our example to an ML system to help you connect the dots better. Let’s use the situation where Australia is sending messages to India using the same coding scheme as was devised for messages from India to Australia.
- The box with balls(in India and Australia) are probability distributions
- When we prepare a machine learning model(classification or regression), what we are doing is approximating a probability distribution and in most cases output the expected value of the probability distribution.
- Devising a coding scheme based on a probability distribution is like preparing a model to output that distribution.
- The box with balls in India is the predicted distribution, because this is the distribution which we assume when we devise the coding scheme.
- The box with the balls in Australia is the true distribution, because this is where the coding scheme is used.
We know the Expected Value of Bits when we use the coding scheme in Australia. It’s the Cross Entropy of Q w.r.t. P (where P is the predicted distribution and Q is the true distribution).

Now, there is some inefficiency as we are using a coding scheme devised for another probability distribution. What is the ideal case here? The predicted distribution is equal to the true distribution. That means if we use a coding scheme devised for Q to send messages. And that is nothing but the Entropy of Q.

Since we have the actual Cross Entropy and the ideal Entropy, the information lost due to the coding scheme is
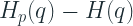

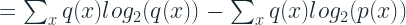


This should also give you some intuition towards why this metric is not symmetric.
Note: We have discussed the entire blog assuming X, the random variable, is a discrete variable. If it is a continuous variable, just replace the 
Applications in Deep Learning
Loss functions are at the heart of a Deep Learning system. The gradients that we propagate to adjust the weights originate from this loss function. The most popular loss functions in classification problems are derived from Information Theory, specifically Entropy.
Categorical Cross Entropy Loss
In an N-way classification problem, the neural network, typically, has N output nodes(with an exception for a binary classification, which has just one node). These nodes’ outputs are also called the logits. Logits are the real valued output of a Neural Network before we apply an activation. If we pass these logits through a softmax layer, the outputs will be transformed into something resembling the probability(statisticians will be turning in their graves now) that the sample is that particular class.
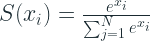

Essentially, a softmax converts the raw logits to probabilities. And since we now have probabilities, we can calculate the Cross Entropy as we have reviewed earlier.
In Machine Learning terms, the Cross Entropy formula is:

where N is the number of samples, C is the number of classes, y is the true probability and y_hat is the predicted probability. In a typical case, y would be the one-hot representation of the target label(with zeroes everywhere and one for the correct label).
Cross Entropy and Log Likelihood
Probability vs. Likelihood
Likelihood, in non-technical parlance, is interchangeably used with probability. But in statistics, and by extension Machine Learning, it has different meaning. In a very curt manner, Probability is when we are talking about outcomes, and Likelihood is for hypothesis.
Let’s take an example of a normal distribution, with mean 30 and standard deviation 2.5. We can find the probability that the drawn value from the distribution is 32.

Now let’s reverse the situation, and consider that we do not know the underlying distribution. We just have the observations drawn from the distribution. In such a case, we can still calculate the probability like before assuming a particular distribution.

Now we are finding the likelihood that a particular observation is described by the assumed parameters. And when we maximise this likelihood, we would arrive at the parameters which best fit the drawn samples. This is the likelihood.
To summarize:


And in machine learning, since we try to estimate the underlying distribution from data, we always try to maximise the Likelihood and this is called Maximum Likelihood Estimation. In practice we maximise the log likelihood rather than the likelihood.
The Math

where N is the number of samples, and f is a function which gives the probability of y given covariates x and parameters.
There are two difficulties when we deal with the above product term:
- From a maths standpoint, it’s easier to work with integrations and derivatives when its a summation
- From a computer science standpoint, multiplying lot of small numbers would result in in really small numbers and consequently arithmetic underflow
This is where Log Likelihood comes in. If we apply the log function, the product turns into a summation. And since log is a monotonic transformation, maximising log likelihood would also maximise the likelihood. So, as a matter of convenience, we almost always maximise log likelihood instead of the pure likelihood.

Cross Entropy = Log Likelihood
Let’s consider q as the true distribution and p as the predicted distribution. y is the target for a sample and x is the input features.
The ground truth distribution, typically, is a one-hot representation over the possible labels.

For a sample 
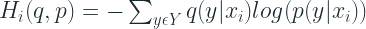
where Y is the set of all labels
The term 



where
Now summing up over all N samples,
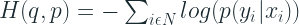
which is nothing but the negative of the log likelihood. So maximising log likelihood is equivalent to minimising the Cross Entropy.
Binary Cross Entropy Loss
In a binary classification, the neural network only has a single output, typically passed through a sigmoid layer. The sigmoid layer as show below squashes the logits to a value between 0 and 1.
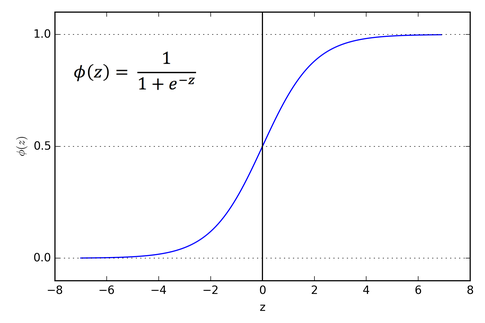
Therefore the output of a sigmoid layer acts like a probability for the event. So if we have two classes, 0 and 1, as the confidence of the network increases about the sample being ‘1’, the output of the sigmoid layer also becomes closer to 1, and vice versa.
Binary Cross Entropy(BCE) is a loss function specifically tailored for a binary classification. Let’s start with the formula and then try to draw parallels to what we have learnt so far.
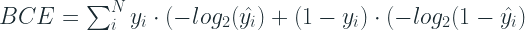
Although the formula might look unfamiliar at first glance, this is just a special case of the Cross Entropy that we reviewed earlier. Unlike the multi-class output, we have just one output which is between 0 and 1. Therefore, to apply the Cross Entropy formula, we synthetically create two output nodes, one with y and another with 1-y (we know from the laws of probability that in a binary outcome, the probabilities sum to 1), and sum the Cross Entropy of all the outcomes.

Kullback-Leibler Divergence Loss
We know KL Divergence is not symmetric. If p is the predicted distribution and q is the true distribution, there are two ways you can calculate KL Divergence.


The first one is called the Forward KL Divergence. It gives you how much the predicted is diverging from the true distribution. The second one is called Backward KL Divergence. It gives you how much the true is diverging from the predicted distribution.
In supervised learning, we use the Forward KL Divergence because it can be shown that maximising the forward KL Divergence is equivalent to maximising the Cross Entropy (which we will detail in the maths section), and Cross Entropy is much easier to calculate. And for this reason, Cross Entropy is preferred over KL Divergence is most simple use cases. Variational Autoencoders and GANs are a few areas where KL Divergence becomes useful again.
Backward KL Divergence is used in Reinforcement Learning and encourages the optimisation to find the mode of the distribution, when Forward KL does the same for the mean. For more details on the Forward vs Backward KL Divergence, read the blogpost by Dibya Ghosh[3]
The Math
We know that KL Divergence is the difference between Cross Entropy and Entropy.

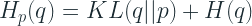
Therefore, our Cross Entropy Loss over N samples is:
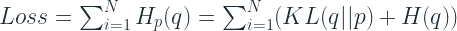
Now the optimisation objective is to minimise this loss by changing the parameters which parameterize predicted distribution p. Since H(q) is the entropy of the true distribution, independent of the parameters, it can be considered as a constant. And while optimising, we know a constant is immaterial and can be ignored. So the Loss becomes:

So, to summarise, we started with the Cross Entropy loss and proved that minimising the Cross Entropy is equivalent to minimising the KL Divergence.
Implementation in Popular Deep Learning Frameworks
The way these losses are implemented in the popular Deep Learning Frameworks like PyTorch and Tensorflow are a little confusing. This is especially true for PyTorch.
PyTorch
- binary_cross_entropy – This expects the logits to be passed through a sigmoid layer before computing the loss
- binary_cross_entropy_with_logits – This expects the raw outputs or the logits to be passed to the loss. The loss implementation applies a sigmoid internally
- cross_entropy – This expects the logits as the input and it applies a softmax(technically a log softmax) before calculating the entropy loss
- nll_loss – This is the plain negative log likelihood loss. This expects the logits to be passed through a softmax layer before computing the loss
- kl_div – This expects the logits to be passed through a softmax layer before computing the loss

Tensorflow 2.0 / Keras
All the Tensorflow 2.0 losses expects probabilities as the input by default, i.e. logits to be passed through Sigmoid or Softmax before feeding to the losses. But they provide a parameter from_logits which is set to True will accept logits and do the conversion to probabilities inside.
- BinaryCrossentropy – Calculates the BCE loss for a y_true and y_pred. y_true and y_pred are single dimensional tensors – a single value for each sample.
- CategoricalCrossentropy – Calculates the Cross Entropy for a y_true and y_pred. y_true is a one-hot representation of labels and y_pred is a multi-dimensional tensor – # of classes values for each sample
- SparseCategoricalCrossentropy – Calculates the Cross Entropy for a y_true and y_pred. y_true is a single dimensional tensor-a single value for each sample- and y_pred is a multi-dimensional tensor – # of classes values for each sample
- KLDivergence – Calculates KL Divergence from y_pred to y_true. This is an exception in the sense that this always expects probabilities as the input.
We have come to the end of the blog and I hope by now you have a much better understanding and intuition about the magical loss functions which make Deep Learning possible.
References
- Shannon, C.E. (1948), “A Mathematical Theory of Communication”, Bell System Technical Journal, 27, pp. 379–423 & 623–656, July & October, 1948.
- Chris Olah, Visual Information, colah.github.io
- Dibya Ghosh, KL Divergence for Machine Learning, http://www.dibyaghosh.com

One thought on “Deep Learning and Information Theory”