

In the last post in the series, we defined what interpretability is and looked at a few interpretable models and the quirks and ‘gotchas’ in it. Now let’s dig deeper into the post-hoc interpretation techniques which is useful when you model itself is not transparent. This resonates with most real world use cases, because whether we like it or not, we get better performance with a black box model.
Data Set
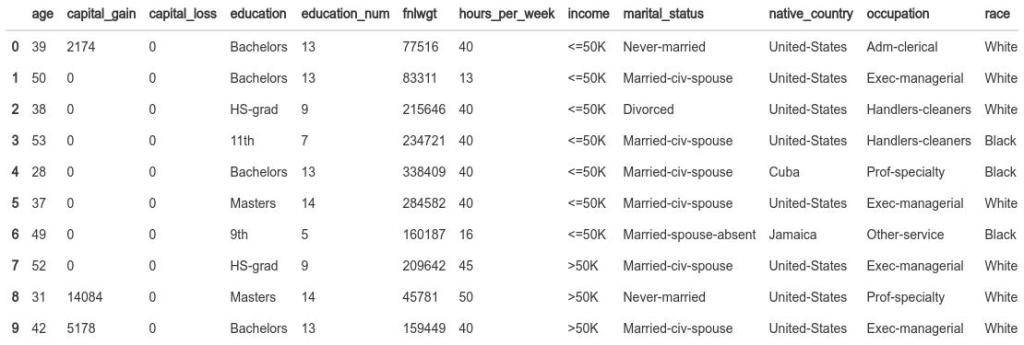
For this exercise, I have chosen the Adult dataset a.k.a Census Income dataset. Census Income is a pretty popular dataset which has demographic information like age, occupation, along with a column which tells us if the income of the particular person >50k or not. We are using this column to run a binary classification using Random Forest. The reasons for choosing Random Forest are two fold:
- Random Forest is one of the most popularly used algorithm, along with Gradient Boosted Trees. Both of them are from the family of ensemble algorithms with Decision Trees.
- There are a few techniques which is specific to tree based models which I want to discuss.

Post-hoc Interpretation
Now let’s look at techniques to do post-hoc interpretation to understand our black box models. All through the rest of the blog, the discussion will be based on machine learning models(and not deep learning) and will be based on structured data. While many of the methods here are model agnostic, since there are a lot of specific ways to interpret deep learning models, especially on unstructured data, we leave that out of our current scope.(May be another blog, another day.)
Data Preprocessing
- Encoded the target variable into numerical variables
- Dealt with missing values
- Transformed marital_status into a binary variable by combining a few values
- Dropped education because education_num gives the same info, but in numerical format
- Dropped capital_gain and capital_loss because they do not have any information. More than 90% of them are zeroes
- Dropped native_country because of high cardinality and skew towards US
- Dropped relationship because of a lot of overlap with marital_status
A Random Forest algorithm was tuned and trained on the data with 83.58% performance. It is a decent score considering the best scores vary from 78-86% based on the way you model and test set. But for our purposes, the model performance is more than enough.
1. Mean Decrease in Impurity
This is by far the most popular way of explaining a tree based model and it’s ensembles. A lot of it is because of Sci-Kit Learn and its easy to use implementation of the same. Fitting a Random Forest or a Gradient Boosting Model and plotting the “feature importance” has become the most used and abused technique among Data Scientist.
The mean decrease in impurity importance of a feature is computed by measuring how effective the feature is at reducing uncertainty (classifiers) or variance (regressors) when creating decision trees within any ensemble Decision Tree method(Random Forest, Gradient Boosting, etc.).
The advantages of the technique are:
- A fast and easy way of getting feature importance
- Readily available in Sci-kit Learn and Decision Tree implementation in R
- It is pretty intuitive to explain to a layman
Algorithm
- During tree construction, whenever a split is made, we keep track of which feature made the split, what was the Gini impurity before and after, and how many samples did it affect
- At the end of the tree building process, you calculate total gain in Gini Index attributed to each feature
- And in case of a Random Forest or a Gradient Boosted Trees, we average this score over all the trees in the ensemble
Implementation
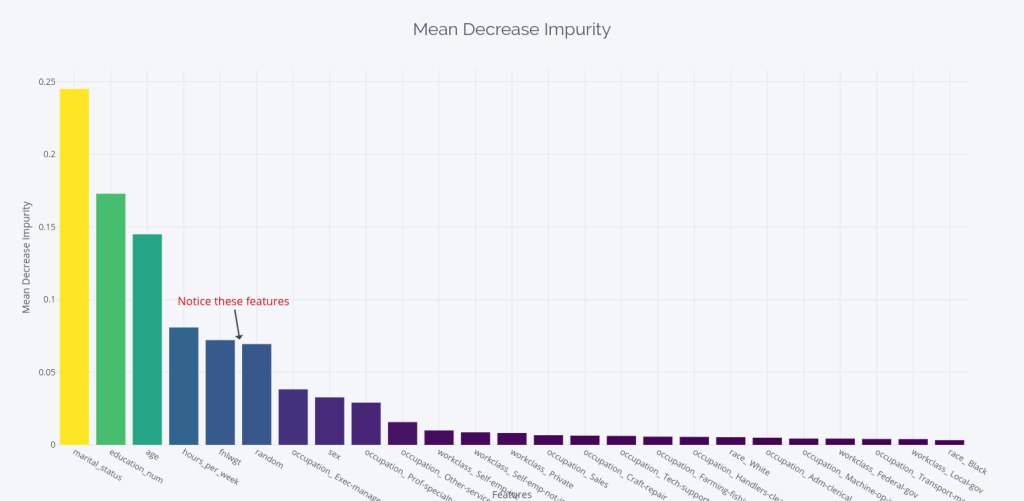
Sci-kit Learn implements this by default in the “feature importance” in tree based models. So retreiving them and plotting top 25 features is very simple.
feat_imp = pd.DataFrame({'features': X_train.columns.tolist(), "mean_decrease_impurity": rf.feature_importances_}).sort_values('mean_decrease_impurity', ascending=False)
feat_imp = feat_imp.head(25)
feat_imp.iplot(kind='bar',
y='mean_decrease_impurity',
x='features',
yTitle='Mean Decrease Impurity',
xTitle='Features',
title='Mean Decrease Impurity',
)
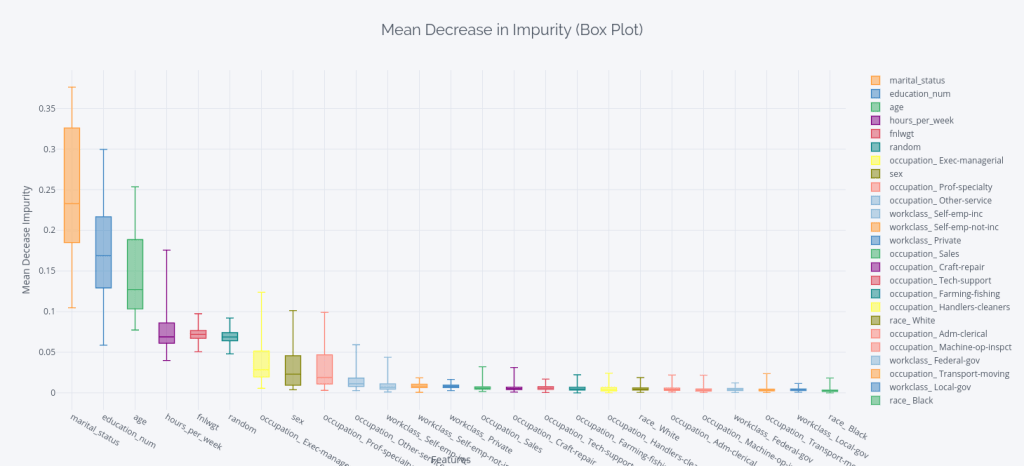
We can also retrieve and plot the mean decrease in impurity of each tree as a box plot.
# get the feature importances from each tree and then visualize the
# distributions as boxplots
all_feat_imp_df = pd.DataFrame(data=[tree.feature_importances_ for tree in
rf],
columns=X_train.columns)
order_column = all_feat_imp_df.mean(axis=0).sort_values(ascending=False).index.tolist()
all_feat_imp_df[order_column[:25]].iplot(kind='box', xTitle = 'Features', yTitle='Mean Decease Impurity')
Interpretation
- The top 4 features are marital status, education_num, age, and hours_worked. This makes perfect sense, as they have a lot to do with how much you earn
- Notice the two features fnlwgt and random in there? Are they more important than the occupation of a person?
- One other caveat here is that we are looking at the one-hot features as separate features and it may have some bearing on why the occupation features are ranked lower than random. Dealing with One-hot features when looking at feature importance are a whole other topic
Let’s take a look at what fnlwgt and random are.
- The description of the dataset for fnlwgt is a long and convoluted description of how the census agency uses sampling to create “weighted tallies” of any specified socio-economic characteristics of the population. In short, it is a sampling weight and nothing to do with how much a person earns
- And random is just what the name says. Before fitting the model, I made a column with random numbers and called it random
Now, surely, these features cannot be more important than other features like occupation, work_class, sex etc. If that is the case, then something is wrong.
The Joker in the Pack a.k.a. the ‘gotcha’
Of course… there is. The mean decrease in impurity measure is a biased measure of feature importance. It favours continuous features and features with high cardinality. In 2007 Strobl et al [1] also pointed out in Bias in random forest variable importance measures: Illustrations, sources and a solution that “the variable importance measures of Breiman’s original Random Forest method … are not reliable in situations where potential predictor variables vary in their scale of measurement or their number of categories.”
Let’s try to understand why it is biased. Remember how the mean decrease in impurity is calculated? Each time a node is split on a feature, the decrease in gini index is recorded. And when a feature is continuous, or have high cardinality, the feature may be split many more times than other features. This inflates the contribution of that particular feature. And what does our two culprit features have in common- they are both continuous variables.
2. Drop Column Importance a.k.a Leave One Co-variate Out (LOOC)
Drop Column feature importance is another intuitive way of looking at the feature importance. As the name suggests, it’s a way of iteratively removing a feature and calculating the different in performance.
The advantages of the technique are:
- Gives a pretty accurate picture of the predictive power of each feature
- One of the most intuitive way to look at feature importance
- Model agnostic. Can be applied to any model
- The way it is calculated, it automatically takes into account all the interactions in the model. If the information in a feature is destroyed, all it’s interactions are also destroyed
Algorithm
- Use your trained model parameters and calculate the metric of your choice on an OOB sample. You can use crossvalidation to get the score. This is your baseline.
- Now, drop one column at a time from your training set, and retrain the model(with same parameters and random state) and calculate the OOB score.
- Importance = OOB score – Baseline
Implementation
def dropcol_importances(rf, X_train, y_train, cv = 3):
rf_ = clone(rf)
rf_.random_state = 42
baseline = cross_val_score(rf_, X_train, y_train, scoring='accuracy', cv=cv)
imp = []
for col in X_train.columns:
X = X_train.drop(col, axis=1)
rf_ = clone(rf)
rf_.random_state = 42
oob = cross_val_score(rf_, X, y_train, scoring='accuracy', cv=cv)
imp.append(baseline - oob)
imp = np.array(imp)
importance = pd.DataFrame(
imp, index=X_train.columns)
importance.columns = ["cv_{}".format(i) for i in range(cv)]
return importance
Let’s do a 50 fold cross validation to estimate our OOB score. (I know it’s excessive, but let’s keep it to increase the samples for our boxplot) Like before, we are plotting the mean decrease in accuracy as well as the boxplot to understand the distribution across cross validation trials.
drop_col_imp = dropcol_importances(rf, X_train, y_train, cv=50)
drop_col_importance = pd.DataFrame({'features': X_train.columns.tolist(), "drop_col_importance": drop_col_imp.mean(axis=1).values}).sort_values('drop_col_importance', ascending=False)
drop_col_importance = drop_col_importance.head(25)
drop_col_importance.iplot(kind='bar',
y='drop_col_importance',
x='features',
yTitle='Drop Column Importance',
xTitle='Features',
title='Drop Column Importances',
)
all_feat_imp_df = drop_col_imp.T
order_column = all_feat_imp_df.mean(axis=0).sort_values(ascending=False).index.tolist()
all_feat_imp_df[order_column[:25]].iplot(kind='box', xTitle = 'Features', yTitle='Drop Column Importance')


Interpretation
- The top 4 features are still marital status, education_num, age, and hours_worked.
- fnlwgt is pushed down the list and now features after some of the one-hot encoded occupations.
- random still occupies a high rank, positioning itself right after the hours_worked
As expected, the fnlwgt was much less important that we was led to believe from the Mean Decrease in Impurity importance. The high position of the random perplexed me a little bit and I re-ran the importance calculation considering all one-hot features as one. i.e. dropping all the occupation columns and checking the predictive power of the occupation. When I do that, I can see random and fnlwgt rank lower than occupation, and workclass. At the risk of making the post bigger than it already is, let’s leave that investigation for another day.
So, have we got the perfect solution? The results are aligned with the Mean Decrease in Impurity, they make coherent sense, and they can be applied to any model.
Joker in the Pack
The kicker here is the computation involved. To carry out this kind of importance calculation, you have to train a model multiple times, one for each feature you have and repeat that for the number of cross validation loops you want to do. Even if you have a model which trains under a minute, the time required to calculate this explodes as you have more features. To give you an idea, it took 2 hr 44 mins for me to calculate the feature importance with 36 features and 50 cross validation loops (which, of course, can be improved with parallel processing, but you get the point). And if you have a large model which is takes two days to train, then you can forget about this technique.
Another concern I have with this method is that since we are retraining the model every time with new set of features, we are not doing a fair comparison. We remove one column and train the model again, it will find another way to derive the same information if it can, and this gets amplifies when there are collinear features. So we are mixing two things when we investigate – the predictive power of the feature and the way the model configures itself.
3. Permutation Importance
The permutation feature importance is defined to be the decrease in a model score when a single feature value is randomly shuffled [2]. This technique measures the difference in performance if you permute or shuffle a feature vector. The key idea is that a feature is important, if the model performance drops if that feature is shuffled.
The advantages of this technique are:
- It is very intuitive. What is the drop in performance if the information in a feature is destroyed by shuffling it?
- Model agnostic. Even though the method was initially developed for Random Forest by Brieman, it was soon adapted to a model agnostic framework
- The way it is calculated, it automatically takes into account all the interactions in the model. If the information in a feature is destroyed, all it’s interactions are also destroyed
- The model need not be retrained and hence we save on computation
Algorithm
- Calculate a baseline score using the metric, trained model, the feature matrix and the target vector
- For each feature in the feature matrix, make a copy of the feature matrix.
- Shuffle the feature column, pass it through the trained model to get a prediction and use the metric to calculate the performance.
- Importance = Baseline – Score
- Repeat for N times for statistical stability and take an average importance across trials
Implementation
The permutation importance is implemented in at least three libraries in python – ELI5, mlxtend, and in a development branch of Sci-kit Learn. I’ve picked the mlxtend version for purely no other reason other than convenience. According to Strobl et al. [3], “the raw [permutation] importance… has better statistical properties.” as opposed to normalizing the importance values by dividing by the standard deviation. I have checked the source code for mlxtend and Sci-kit Learn and they do not normalize them.
from mlxtend.evaluate import feature_importance_permutation
#This takes sometime. You can reduce this number to make the process faster
num_rounds = 50
imp_vals, all_trials = feature_importance_permutation(
predict_method=rf.predict,
X=X_test.values,
y=y_test.values,
metric='accuracy',
num_rounds=num_rounds,
seed=1)
permutation_importance = pd.DataFrame({'features': X_train.columns.tolist(), "permutation_importance": imp_vals}).sort_values('permutation_importance', ascending=False)
permutation_importance = permutation_importance.head(25)
permutation_importance.iplot(kind='bar',
y='permutation_importance',
x='features',
yTitle='Permutation Importance',
xTitle='Features',
title='Permutation Importances',
)
We also plot a box plot of all trials to get a sense of the deviation.
all_feat_imp_df = pd.DataFrame(data=np.transpose(all_trials),
columns=X_train.columns, index = range(0,num_rounds))
order_column = all_feat_imp_df.mean(axis=0).sort_values(ascending=False).index.tolist()
all_feat_imp_df[order_column[:25]].iplot(kind='box', xTitle = 'Features', yTitle='Permutation Importance')


Interpretation
- The top 4 remains the same, but the first three(marital_status, education, age) are much more pronounced in the permutation importance
- fnlwgt and random does not even make it to the top 25
- Being an Exec Manager, or Prof-speciality has a lot to do with whether you are earning >50k or not
- All in all, it resonates with our mental model of the process
Everything is hunky-dory in feature importance land? Have we got the best way of explaining what features the model is using for predictions?
The Joker in the Pack
We know from life that nothing is perfect and neither is this technique. It’s Achilles’ Heel is correlation between features. Just like drop column importance, this technique is also affected by the effect of correlation between features. Strobl et al. in Conditional variable importance for random forests [3] showed that “permutation importance over-estimates the importance of correlated predictor variables.” Especially in ensemble of trees, if you have two correlated variables, some of the trees might have picker feature A and some others might have picked feature B. And while doing this analysis, in the absence of feature A, the trees which picked feature B would work well and keep the performance high and vice versa. What this will result in is that both the correlated features A and B will have inflated importance.
Another drawback of the technique is that the core idea in the technique is about permuting a feature. But that is essentially a randomness which is not in our control. And because of this the results may vary greatly. We don’t see it here, but if the box plot shows a large variation in importance for a feature across trials, I’ll be wary in my interpretation.
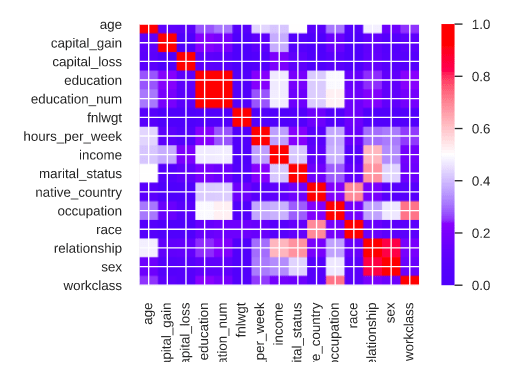
 Correlation Coefficient [7](in-built in pandas profiling which considers categorical variables as well)
Correlation Coefficient [7](in-built in pandas profiling which considers categorical variables as well)There is yet another drawback to this technique, which in my opinion is the most concerning. Giles Hooker et al. [6] says, “When features in the training set exhibit statistical dependence, permutation methods can be highly misleading when applied to the original model.”
Let’s consider occupation and education. We can understand this from two perspectives:
- Logical: If you think about it, occupation and education have a definite dependence. You can only get a few jobs if you have the sufficient education and statistically you can draw parallels between them. So if we are permuting any one of those columns, it would create feature combinations which does not make sense. A person with education as 10th and occupation as Prof-speciality doesn’t make a lot of sense, does it? So, when we are evaluating the model, we are evaluating nonsensical cases like these which muddles up the metric which we use to assess the feature importance.
- Mathematical: occupation and education have strong statistical dependence(we can see that from the correlation plot above). So, when we are permuting any one of these features, we are forcing the model to explore unseen sub-spaces in the high-dimensional feature space. And this forces the model to extrapolate and this extrapolation is a significant source of error.
Giles Hooker et al. [6] suggests alternative methodologies which combine LOOC and Permutation methods, but all the alternatives are computationally more intensive and does not have a strong theoretical guarantee of having better statistical properties.
Dealing with correlated features
After identifying the highly correlated features, there are two ways of dealing with correlated features.
- Group the highly correlated variables together and evaluate only one feature from the group as a representative of the group
- When you permute the columns, permute the whole group of features in one trial.
N.B. The second method is the same method that I would suggest to deal with one-hot variables.
Sidenote (Train or Validation)
During the discussion of both Drop Column importance and Permutation importance, one question should have come to your mind. We passed the test/validation set to the methods to calculate the importance. Why not train set?
This is a grey area in the application of some of these methods. There is no right or wrong here because there are arguments for and against both. In Interpretable Machine Learning, Christoph Molnar argues a case for both train and validation sets.
The case for test/validation data is a no-brainer. For the same reason why we do not judge a model by the error in the training set, we cannot judge the feature importance on the performance on the training set (especially since the importance is intrinsically linked to the error).
The case for train data is counter-intuitive. But if you think about it, you’ll see that what we want to measure is how the model is using the features. And what better data to judge that than the training set on which the model was trained? Another trivial issue is also that we would ideally train the model on all available data and in such an ideal scenario, there will not be a test or validation data to check performances on. In Interpretable Machine Learning[5], section 5.5.2 discusses this issue at length and even with a synthetic example of an overfitting SVM.
It all comes down to whether you want to know what features the model relies on to make predictions or the predictive power of each feature on unseen data. For eg. if you are evaluating feature importance in the context of feature selection, do not use test data in any circumstances(there you are overfitting your feature selection to fit the test data)
4. Partial Dependence Plots (PDP) and Individual Conditional Expectation (ICE) plots
All the techniques we reviewed till now looked at the relative importance of different features. Now let’s move slightly in a different direction and look at a few techniques which explore how a particular feature interact with the target variable.
Partial Dependence Plots and Individual Conditional Expectation plots help us understand the functional relationship between the features and the target. They are graphical visualizations of the marginal effect of a given variable(or multiple variables) on an outcome. Friedman(2001) introduced this technique in his seminal paper Greedy function approximation: A gradient boosting machine[8].
Partial Dependence Plots shows an average effect, whereas ICE plots show the functional relationship for individual observations. PD plots shows the average effect whereas ICE plots show the dispersion or heterogeneity of the effect.
The advantages of this technique are:
- The calculation is very intuitive and is easy to explain in layman terms
- We can understand the relationship between a feature or a combinations of feature with the target variable. i.e. if it is linear, monotonic, exponential etc.
- They are easy to compute and implement
- They give a causal interpretation, as opposed to a feature importance style interpretation. But what we have to keep in mind is that the causal interpretation of how the model sees the world and now the real world.
Algorithm
Let’s consider a simple situation where we plot the PD plot for a single feature x, with unique values 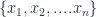
- For
- Copy the training data and replace the original values of x with
- Use the trained model to generate predictions for the modified copy of the entire training data
- Store all the predictions against
in a map like data structure
- Copy the training data and replace the original values of x with
- For PD plot:
- Calculate the average predictions for each
- Plot the pairs
- Calculate the average predictions for each
- For ICE plot:
- Plot all the pairs
. N is the total number of observations in the training set.
- Plot all the pairs
- In practice, instead of taking all the possible values of a feature, we define a grid of intervals for the continuous variable to save on computation.
- For a categorical variable also, this definition holds, But we won’t be defining a grid there. Instead we take all the unique values in the category(or all the one-hot encoded variables pertaining to a categorical feature) and calculate the ICE and PD plots using the same methodology.
- If the process is still unclear to you, I suggest looking at this medium post(by the author of PDPbox, a python library for plotting PD plots.



Implementation
I have found the PD plots implemented in PDPbox, skater and Sci-kit Learn. And the ICE plots in PDPbox, pyCEbox, and skater. Out of all of these, I found PDPbox to be the most polished. And they also support 2 variable PDP plots as well.
from pdpbox import pdp, info_plots
pdp_age = pdp.pdp_isolate(
model=rf, dataset=X_train, model_features=X_train.columns, feature='age'
)
#PDP Plot
fig, axes = pdp.pdp_plot(pdp_age, 'Age', plot_lines=False, center=False, frac_to_plot=0.5, plot_pts_dist=True,x_quantile=True, show_percentile=True)
#ICE Plot
fig, axes = pdp.pdp_plot(pdp_age, 'Age', plot_lines=True, center=False, frac_to_plot=0.5, plot_pts_dist=True,x_quantile=True, show_percentile=True)
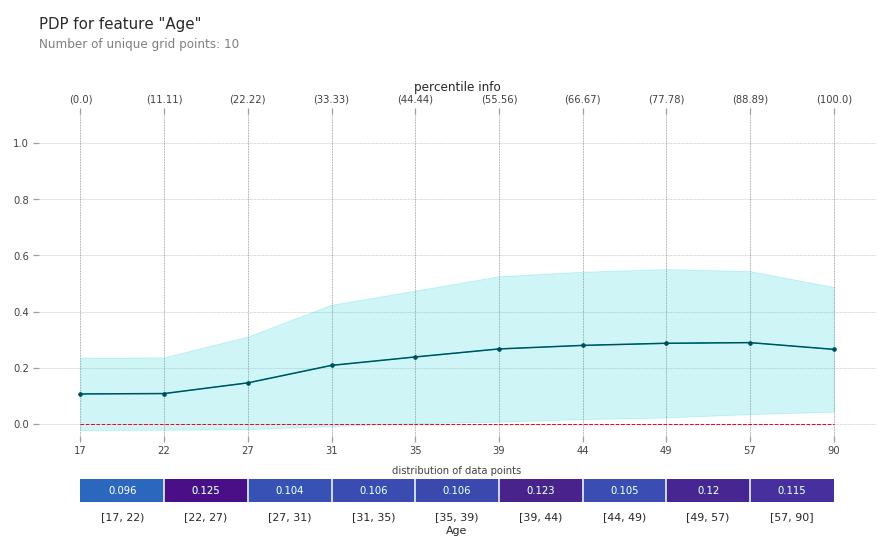
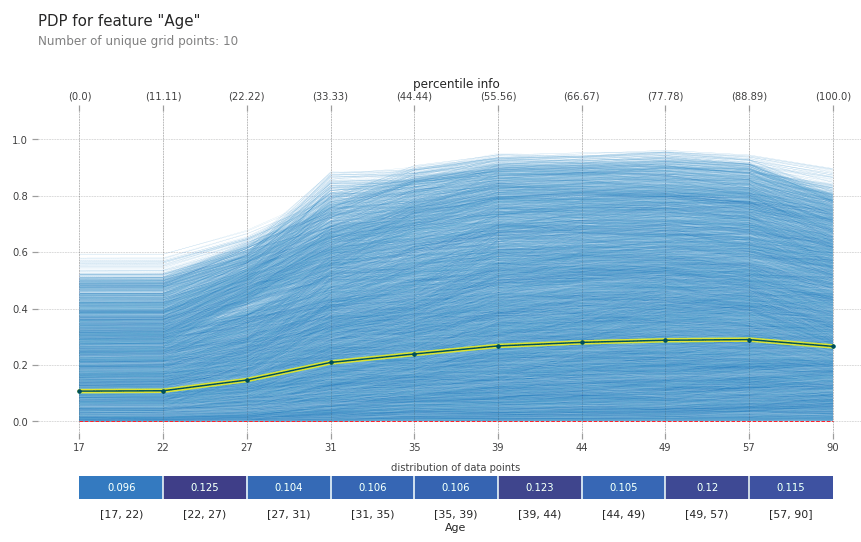
Let me take some time to explain the plot. On the x axis, you can find the values of the feature you are trying to understand, i.e. age. On the y axis you find the prediction. In case of a classification it is the prediction probability and in case of regression it is the real valued prediction. The bar on the bottom represents the distribution of training data points in different quantiles. It helps us gauge the goodness of the inference. The parts where the number of points are very less, the model has seen very less examples and the interpretation can be tricky. The single line in the PD plot shows the average functional relationship between the feature and target. All the lines in the ICE plot shows the heterogeneity in the training data, i.e. how all the observations in the training data vary with the different values of age.
Interpretation
- age has a largely monotonic relationship with the earning capacity of a person. The older a person is, more likely he is to earn above 50k
- The ICE plots shows a lot of dispersion. But all of it shows the same kind of behaviour that we see in the PD plot
- The training observations are considerable well balanced across the different quantiles.
Now, let’s also take an example with a categorical feature, like education. PDPbox has a very nice feature where it lets you pass a list of features as an input and it will calculate the PDP for them considering them as categorical features.
# All the one-hot variables for the occupation feature
occupation_features = ['occupation_ ?', 'occupation_ Adm-clerical', 'occupation_ Armed-Forces', 'occupation_ Craft-repair', 'occupation_ Exec-managerial', 'occupation_ Farming-fishing', 'occupation_ Handlers-cleaners', 'occupation_ Machine-op-inspct', 'occupation_ Other-service', 'occupation_ Priv-house-serv', 'occupation_ Prof-specialty', 'occupation_ Protective-serv', 'occupation_ Sales', 'occupation_ Tech-support', 'occupation_ Transport-moving']
#Notice we are passing the list of features as a list with the feature parameter
pdp_occupation = pdp.pdp_isolate(
model=rf, dataset=X_train, model_features=X_train.columns,
feature=occupation_features
)
#PDP
fig, axes = pdp.pdp_plot(pdp_occupation, 'Occupation', center = False, plot_pts_dist=True)
#Processing the plot for aesthetics
_ = axes['pdp_ax']['_pdp_ax'].set_xticklabels([col.replace("occupation_","") for col in occupation_features])
axes['pdp_ax']['_pdp_ax'].tick_params(axis='x', rotation=45)
bounds = axes['pdp_ax']['_count_ax'].get_position().bounds
axes['pdp_ax']['_count_ax'].set_position([bounds[0], 0, bounds[2], bounds[3]])
_ = axes['pdp_ax']['_count_ax'].set_xticklabels([])
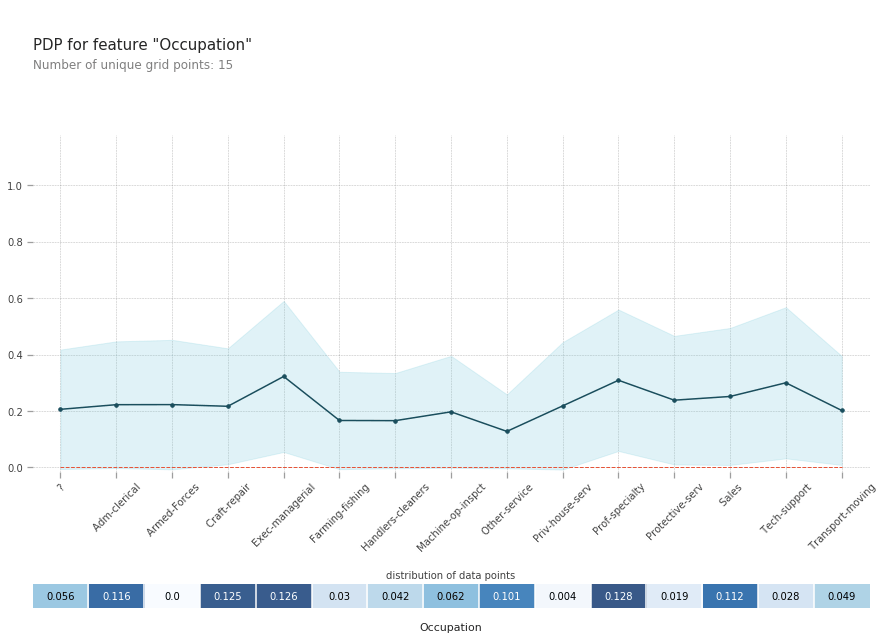
Interpretation
- Most of the occupations have very minimal effect on how much you earn.
- The ones that stand out from the rest are, Exec-managerial, Prof-speciality and Tech Support
- But, from the distribution, we know that there were very little training examples for Tech-support and hence we take that with a grain of salt.
Interaction between multiple features
PD plots can be theoretically drawn for any number of features to show their interaction effect as well. But practically, we can only do it for two, at the max three. Let’s take a look at an interaction plot between two continuous features age and education(education and age are not truly continuous, but for lack of better example we are choosing them).
There are two ways you can plot a PD plot between two features. There are three dimensions here, feature value 1, feature value 2, and the target prediction. Either, we can plot a 3-D plot or a 2-D plot with the 3rd dimension depicted as color. I prefer the 2-D plot because I think it conveys the information in a much more crisp manner than a 3-D plot where you have to look at the 3-D shape to infer the relationship. PDPbox implements the 2-D interaction plots, both as a contour plot and grid. Contour works best for continuous features and grid for categorical features
# Age and Education
inter1 = pdp.pdp_interact(
model=rf, dataset=X_train, model_features=X_train.columns, features=['age', 'education_num']
)
fig, axes = pdp.pdp_interact_plot(
pdp_interact_out=inter1, feature_names=['age', 'education_num'], plot_type='contour', x_quantile=False, plot_pdp=False
)
axes['pdp_inter_ax'].set_yticklabels([edu_map.get(col) for col in axes['pdp_inter_ax'].get_yticks()])

Interpretation
- Even though we observed a monotonic relationship with age when looked at isolation, now we know that is not universal. For eg. look at the contour line to the right of 12th education level. It’s pretty flat as compared to the lines for some-college and above. What it really shows that your probability of getting more than 50k doesn’t only increase with age, but it also has a bearing on your education. A college degree ensures you increase your earning potential as you get older.
This is also a very useful technique to investigate bias(the ethical kind) in your algorithms. Suppose if we want to look at the algorithmic bias in the sex dimension.
#PDP Sex
pdp_sex = pdp.pdp_isolate(
model=rf, dataset=X_train, model_features=X_train.columns, feature='sex'
)
fig, axes = pdp.pdp_plot(pdp_sex, 'Sex', center=False, plot_pts_dist=True)
_ = axes['pdp_ax']['_pdp_ax'].set_xticklabels(sex_le.inverse_transform(axes['pdp_ax']['_pdp_ax'].get_xticks()))
# marital_status and sex
inter1 = pdp.pdp_interact(
model=rf, dataset=X_train, model_features=X_train.columns, features=['marital_status', 'sex']
)
fig, axes = pdp.pdp_interact_plot(
pdp_interact_out=inter1, feature_names=['marital_status', 'sex'], plot_type='grid', x_quantile=False, plot_pdp=False
)
axes['pdp_inter_ax'].set_xticklabels(marital_le.inverse_transform(axes['pdp_inter_ax'].get_xticks()))
axes['pdp_inter_ax'].set_yticklabels(sex_le.inverse_transform(axes['pdp_inter_ax'].get_yticks()))
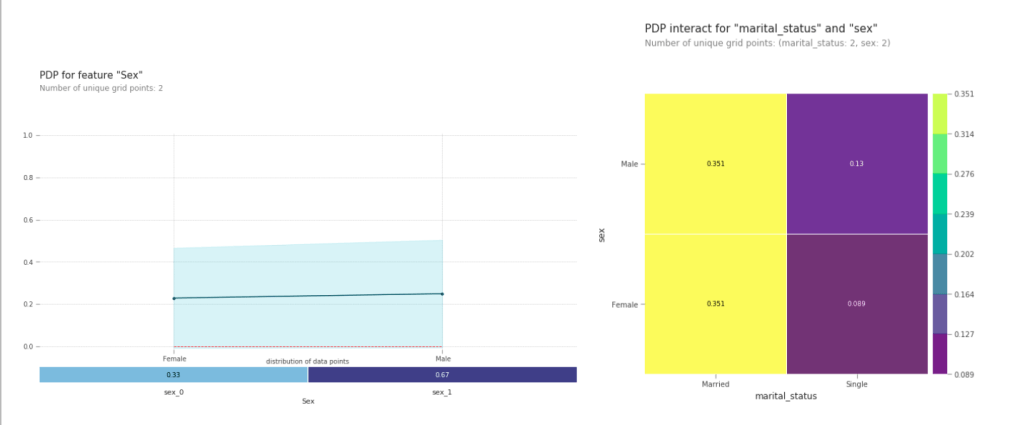
- If we look at just the PD plot of sex, we would come to the conclusion that there is no real discrimination based on the sex of the person.
- But, just take a look at the interaction plot with marital_status. On the left hand side(married), both the squares have the same color and value, but on the right hand side(single) there is a difference between Female and Male
- We can conclude that being a single male gives you a much better chance at getting more than 50k than being a single female. (Although I wouldn’t start an all out war against sexual discrimination based on this, it would definitely be a starting point in the investigation.
Joker in the Pack
The assumption of independence between the features is the biggest flaw in this approach. The same flaw which is present in LOOC importance and Permutation Importance. is applicable to PDP and ICE plots. Accumulated Local Effects plots are a solution to this problem. ALE plots solve this problem by calculating – also based on the conditional distribution of the features – differences in predictions instead of averages.
To summarize how each type of plot (PDP,ALE) calculates the effect of a feature at a certain grid value v:
Partial Dependence Plots: “Let me show you what the model predicts on average when each data instance has the value v for that feature. I ignore whether the value v makes sense for all data instances.”
ALE plots: “Let me show you how the model predictions change in a small”window” of the feature around v for data instances in that window.”
In the python environment, there is no good and stable library for ALE. I’ve only found one ALEpython, which is still very much in development. I managed to get a ALE plot of age, which you can find below. But got an error when I tried an interaction plot. It’s also not developed for categorical features.

This is where we break off again and push the rest of the stuff to the next blog post. In the next part we take a look at LIME, SHAP, Anchors, and more.
Full Code is available in my Github
Blog Series
References
- Strobl, C., Boulesteix, AL., Zeileis, A. et al. BMC Bioinformatics (2007) 8: 25. https://doi.org/10.1186/1471-2105-8-25
- L. Breiman, “Random Forests”, Machine Learning, 45(1), 5-32, 2001. https://doi.org/10.1023/A:1010933404324
- Strobl, C., Boulesteix, A., Kneib, T. et al. Conditional variable importance for random forests. BMC Bioinformatics9, 307 (2008) doi:10.1186/1471-2105-9-307
- Terence Parr, Kerem Turgutlu, Christopher Csiszar, and Jeremy Howard, “Beware Default Random Forest Importances“
- Christoph Molnar, “Interpretable Machine Learning: A Guide for making black box models explainable“
- Giles Hooker, Lucan Mentch, “Please Stop Permuting Features: An Explanation and Alternatives”, arXiv:1905.03151 [stat.ME]
- M. Baak, R. Koopman, H. Snoek, S. Klous, “A new correlation coefficient between categorical, ordinal, and interval variables with Pearson characteristics, arXiv:1811.11440 [stat.ME]
- Friedman, Jerome H. Greedy function approximation: A gradient boosting machine. Ann. Statist. 29 (2001), no. 5, 1189–1232. doi:10.1214/aos/1013203451
- Alex Goldstein et al. “Peeking Inside the Black Box: Visualizing Statistical Learning with Plots of Individual Conditional Expectation”, arXiv:1309.6392 [stat.AP]

5 thoughts on “Interpretability: Cracking open the black box – Part II”